Introduction
If you are confused about input vs output tokens in ai, you are not alone. But this is not just a technical detail. If you do not understand how tokens work, you will overpay for API costs and end up with slower application speeds.
Input tokens are the text you send into a model. Output tokens are the text the model sends back. That split affects pricing, latency, prompt design, and how far your app can scale before costs start creeping up.
Get this part right, and a lot of AI decisions become simpler. You can write tighter prompts, control responses better, and build systems that stay fast and cost-efficient.
Calculate your AI token usage for free ⇒
TL;DR: The Difference Between Input and Output Tokens
Input tokens are the prompt, instructions, and data you send into the AI. Output tokens are the words the AI generates back. Input is usually cheaper and handled faster, while output usually costs more and takes longer because the model has to generate it token by token.
| Difference | Input tokens | Output tokens |
| Definition | The text you send to the model, such as prompts, context, and attached content | The text the model returns as its answer, completion, or generated result |
| Cost | Usually cheaper | Often 3 to 5 times more expensive |
| Speed | Processed fast | Generated more slowly |
This is why a short prompt with a long answer can still get expensive. The real unit of work is not one request, it is the total number of tokens going in and coming out.
What Exactly is an AI Token?
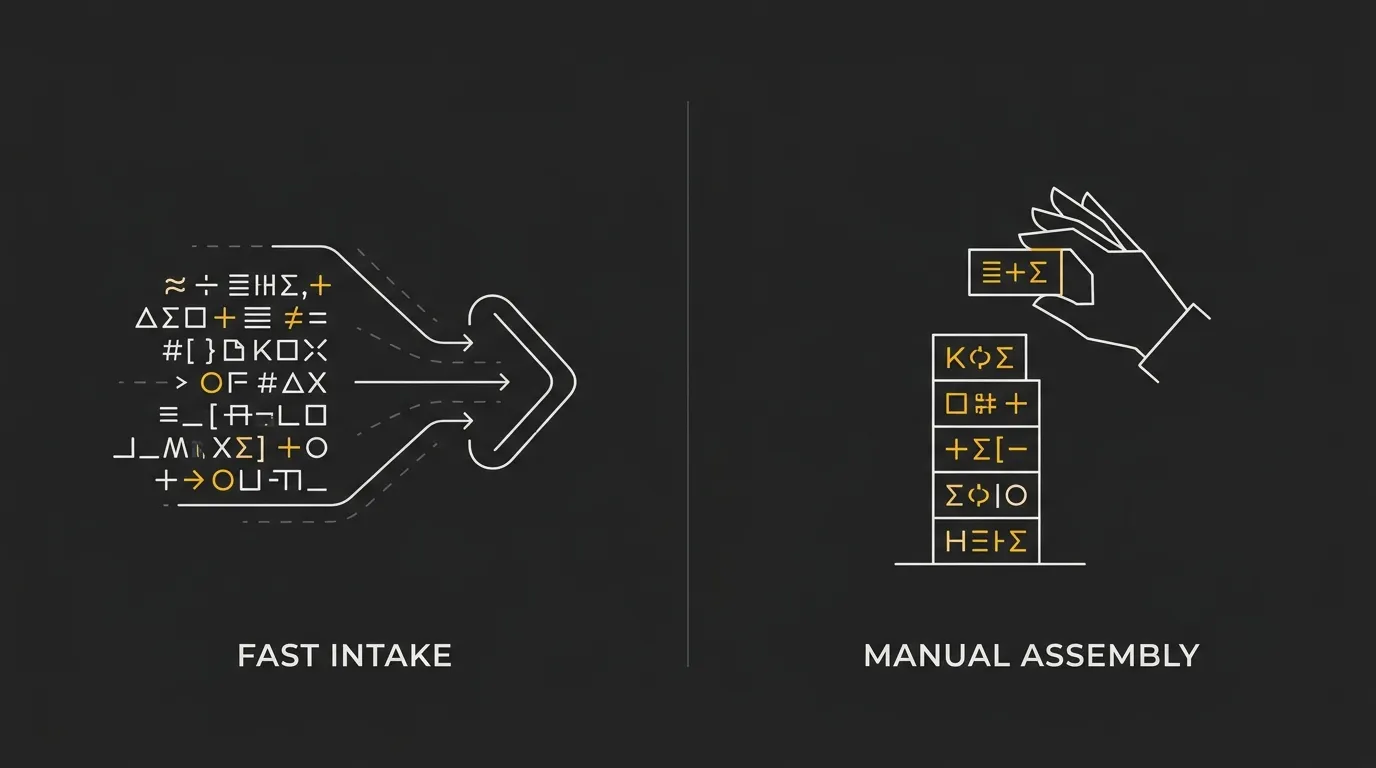
An AI token is a small chunk of text that a model reads and processes, not a full word every time. In plain English, a token is often about 4 characters or roughly three-quarters of a word in English. A simple way to think about it: tokens are like puzzle pieces of language, and the AI reads and builds with those pieces instead of whole sentences at once.
Input Tokens: The Context You Provide
Input tokens are everything you send into the model before it answers. That includes your prompt, system instructions, chat history, and any pasted text, files, logs, or document content that gets included in the request.
In practice, input tokens are the context layer. They tell the AI what role to follow, what task to do, what background to consider, and what source material to read before generating anything back.
The key operational difference is speed. Models process input tokens all at once in parallel, which is why this part is usually very fast and comparatively cheap to run.
That matters more than most people think. If you keep stuffing requests with long documents, tool outputs, or raw debugging data, your input token count climbs fast, and those costs can compound across multi-step workflows.
Output Tokens: The AI’s Response
Output tokens are the text the AI generates and sends back to you. That includes the answer, summary, code, rewrite, or any other completion produced by the model.
Unlike input, output is generated sequentially, one token at a time. That is why responses often appear to stream onto the screen instead of arriving all at once.
This is usually the expensive part of the process. Longer answers take more compute, more time, and more money, and if those long responses get fed into later steps, they can also increase future input costs.
The Pricing Gap: Why Output Tokens Cost 3x to 5x More
The short version: generating text is harder than reading text. That is why providers often price output tokens several times higher than input tokens.
When you send input, the model can process that context in parallel. It reads the whole batch of tokens in a highly efficient pass. That makes the input side relatively cheap.
Output is different. The model has to generate the answer step by step, one token at a time, while constantly using prior context to decide what comes next. In simple business terms, reading a large document is cheaper than writing a custom response word by word.
This is the part that hits budgets. A long prompt can cost less than a long answer, even when the prompt feels bigger. And if a provider offers cached-input discounts, the gap can look even wider in real billing, which is why separating input and output tokens matters when you are estimating API costs.
The Speed Factor: How Tokens Affect Latency

If an AI app feels slow, the bottleneck is usually the output, not the input. The model can process input tokens quickly, but it has to generate output tokens one by one, which is where latency accumulates.
In practical terms, computing a single output token can take well over 100 times longer than processing an input token. That is why a long answer feels slow even when the prompt was short and simple.
This is also why trimming prompts does not always fix speed problems. If you want faster responses, the bigger win is usually reducing how much the model has to write back.
3 Rules to Optimize Your AI Token Costs
If you want cheaper and faster AI, the goal is simple: spend a bit more on input to control output hard. Output is where cost and latency usually blow up.
Give more input to get less output
This sounds backward, but it usually works. Because input tokens are cheaper, giving the model a clearer context upfront can reduce rambling, retries, and overly long answers.
For example, instead of saying fix this and pasting vague instructions, give the exact goal, format, constraints, and source material in one go. A well-loaded prompt often produces a shorter, cleaner answer on the first pass, which can save both money and time.
This is especially useful in business workflows where bad output creates follow-up calls, rewrites, or extra agent steps. More context in, less fluff out.
Chain of Thought is not a free lunch
Telling a model to think step by step can increase token usage fast. More reasoning text usually means more generated output, and generated output is the expensive part.
That does not mean reasoning is bad. It means you should ask for it only when the task actually needs it. If you just need a classification, short summary, extraction, or yes-no decision, asking for a full thought process can burn budget for no real gain.
A good rule is simple: ask for the answer first, not the essay behind the answer.
Use strict formatting constraints
If you do not specify the format, many models will add extra words by default. That means greetings, explanations, filler transitions, and other text you did not need but still pay for.
Be explicit about the output shape:
- Return only the final answer.
- Use a table with these columns only.
- Output valid JSON only.
- Give me 3 bullets max.
- No intro, no explanation, no conclusion.
This is one of the easiest wins. Tight output constraints reduce token count, improve consistency, and make downstream automation much easier.
Stop Guessing, Start Building Systems
Understanding token economics is the first step. The real upside comes when you design workflows that control context, constrain output, and keep costs predictable as volume grows.
That is where most businesses get stuck. They buy access to a model, test a few prompts, and hope it scales. It usually does not. A tool is just a thing you buy, but a system is a thing that works.
If you want AI to produce consistent business output, you need orchestration: the right inputs, the right model routing, the right formatting rules, and the right handoffs between steps. That is how you protect margin and prove out the ROI.
Marcus-Aurelius Engines focuses on building AI content engines and workflows that do exactly that. If you want to build a setup that maximizes output quality without wasting spend, reach out and let’s look at the system.
Start calculating your AI token usage for free ⇒
Frequently Asked Questions
How many words is 1,000 tokens?
1,000 tokens is roughly 750 English words. The exact count varies by writing style, formatting, and the mix of short versus long words.
What are cached input tokens?
Cached input tokens are repeated prompt tokens that a provider can serve from memory instead of fully reprocessing each time. Because they are reused, they are often billed at a discount compared with standard input tokens.
Is token-based pricing the only way AI is billed?
No, token-based pricing is common for text models, but it is not the only pricing model. Some AI products use subscription pricing, and some audio or video systems may use time-based billing instead.