Introduction
If you’re asking what are tokens in ai, you’re probably stuck on the annoying part: why AI pricing feels random and why the model sometimes forgets stuff mid-task.
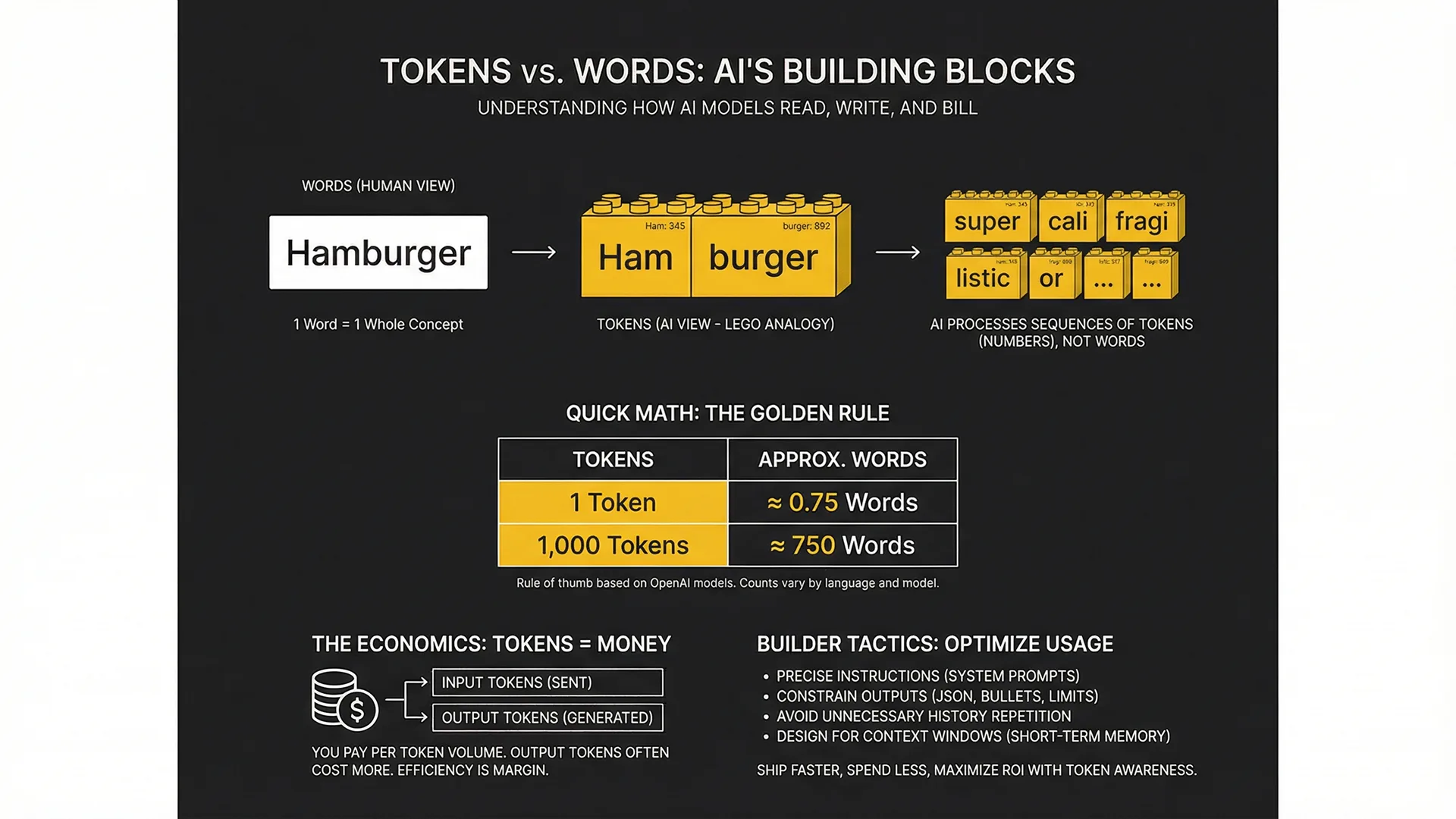
Tokens sound like crypto or arcade coins, but they’re not. They’re just how an AI model reads and writes: it breaks text into small chunks (words, parts of words, punctuation) and processes those chunks as numbers.
Get tokens straight and the rest clicks fast: cost is basically token volume, and “how smart it feels” is often just “how much context it can keep in tokens” while you’re trying to ship.
The TL;DR: What Is a Token Actually?
A token is a chunk of text, sometimes a whole word, sometimes part of a word (or punctuation). AI does not read words, it reads numbers: your text gets split into tokens, those tokens get mapped to numeric IDs, and the model processes those numbers.
The Golden Rule: Words vs. Tokens
Here is the cheat sheet. Memorize this: token counts are not the same as word counts.
OpenAI-style rule of thumb:
- 1 token ≈ 0.75 words
- 1,000 tokens ≈ 750 words
Quick Math Table
Insert the Quick Math table here (using the conversions above) so readers can eyeball tokens to words at a glance.
Explaining for Dummies: How It Works
Tokenization is just the step where the AI takes your text and chops it into bite-sized pieces it can handle. Those pieces are tokens, and everything the model does starts with that split.
The LEGO Analogy
Think of your prompt like a LEGO build.
You hand the model a finished-looking thing (a sentence), but the model cannot work with the finished thing directly. It breaks it down into LEGO bricks (tokens), snaps those bricks into a long line, and uses that line to figure out what comes next.
What this means in practice:
- The model is not reading like a human, it is processing a sequence of small pieces.
- The more pieces you give it (longer prompts, lots of pasted text), the more it has to carry while it answers.
- The answer it produces is also built out of tokens, brick by brick.
Why ‘Hamburger’ might be one token but ‘supercalifragilistic’ is many
Tokenizers are basically optimizers: they try to use the biggest, most common chunks they recognize. Common words and common word parts tend to stay intact, so they often come out as fewer tokens.
Rare, weird, or long words tend to get chopped up into multiple chunks. Same deal for:
- Made-up terms, brand-new slang, or niche jargon
- Long strings with no spaces (some URLs, code-y identifiers)
- Text with lots of symbols and formatting
Bottom line: if the model has to split your text into more tokens, you are spending more of the model’s attention and budget on the same meaning. Keep prompts clean, use normal wording when you can, and only get fancy when you need to.
Context Windows: Why Your AI Forgets Stuff
Every AI model has a fixed token budget for what it can hold in working memory at one time. That budget is the context window, and it is basically the model’s short-term memory.
Here is the part that surprises people building real workflows: your input tokens plus the model’s output tokens both count. So a long prompt plus a long answer can blow the budget faster than you expect.
When you go over the context window, the model cannot keep everything in view. It will start dropping older parts of the conversation (usually the beginning) to make room for newer tokens. From the outside, that looks like it forgot what you said, changed its mind, or started making things up because it is missing key details.
Practical takeaway: if you paste a whole book, do not be shocked when it forgets chapter one.
To make this usable in production-style flows, design for the context window instead of fighting it:
- Keep prompts tight and remove filler text.
- Summarize or compress earlier content before you continue.
- Store facts outside the chat (for example: a small always-loaded set of key details plus a separate retrieval layer for longer reference material), then pull only what you need back into the prompt.
The Economics: Tokens = Money
Most AI APIs bill by token volume, typically priced per million tokens. That means tokens are not an abstract technical detail, they are your meter: the more tokens you send and receive, the more you pay.
Input vs. Output Pricing
There are two token streams in any call, and they usually do not cost the same.
- Input tokens: Everything you send the model, your prompt, system instructions, tool outputs, pasted docs, chat history.
- Output tokens: Everything the model generates back, the answer, the rewrite, the code, the JSON.
In many pricing plans, input tokens are cheaper than output tokens. Even when the gap is small, output tokens can still dominate spend because models can generate a lot of text fast, especially if you do not put boundaries on length and format.
Why Efficiency Matters for ROI
If you are using AI inside a workflow (content ops, support, lead research, internal tools), token efficiency is margin. Sloppy prompts burn cash: extra context you did not need, meandering answers you did not ask for, and repeated back-and-forth because the request was vague.
Marcus-Aurelius Digital obsesses over this for the same reason you obsess over page speed or CAC: small efficiency gains compound at scale. Practical ways to keep token spend tied to outcomes:
- Ask for constrained outputs (specific format, length, or fields) so you do not pay for essays you will not use.
- Avoid pasting huge blobs by default; retrieve only the relevant chunk you need for the current step.
- Cache or reuse stable context (brand voice rules, product facts) instead of resending it every time, when your stack allows it.
Builder Tactics: Optimizing Your Token Usage
Lazy prompting costs you speed and money. The pattern is always the same: too much context in, too much rambling out, then extra retries because the model guessed wrong.
Stop summarizing history unnecessarily
Issue: You keep re-sending long chat history or big summaries just in case, and your input tokens explode.
Fix: Only send what the model needs for the next step.
- For ongoing projects, keep a small, stable context block (goal, constraints, definitions), and pass only the relevant excerpt of source material per task.
- If you need continuity, use short checkpoints (one tight summary) instead of dumping the entire transcript every time.
Use precise instructions (System Prompts)
Issue: Vague prompts create back-and-forth, and each clarification round burns tokens.
Fix: Be direct and specific up front.
- State the task, the audience, the constraints (format, length, must-include, must-avoid), and what success looks like.
- Put stable rules in a system prompt (or an equivalent always-on instruction layer) so you do not repeat them in every message.
Ask for JSON or Bullet points
Issue: Free-form paragraphs are expensive to generate and expensive to clean up downstream.
Fix: Constrain the output so it is short and usable.
- Ask for JSON when you plan to parse or automate the result.
- Ask for bullet points when you just need decisions, options, or a checklist.
- Add a hard limit (for example: max items, max sections, or a tight word budget) to control output tokens.
Conclusion: Ship Faster, Spend Less
Tokens are the fuel. They are how the model reads, how it thinks (in sequence), and how you get billed. When you manage tokens on purpose, you get AI systems that are faster, more reliable, and cheaper to run.
The play is simple: keep inputs tight, constrain outputs, and design workflows that do not depend on the model remembering everything forever. Do that and you stop paying for noise, and start paying for outcomes.
If you want to build high-ROI AI systems that actually drive revenue (without burning money on bad workflows), check out Marcus-Aurelius Digital. We build systems that print results. Let’s work.
Frequently Asked Questions
How many words is 1,000 tokens?
About 750 words, using the common rule of thumb that 1 token is roughly 0.75 words. It varies by language and formatting.
Do spaces and punctuation count as tokens?
Yes, spaces and punctuation can count because the model tokenizes raw text, not just words. Exact tokenization depends on the model’s tokenizer.
Why is GPT-4 more expensive than GPT-4o mini?
Smarter, higher-capability models typically require more compute per token, so providers price them higher. Smaller models are cheaper per token because they are lighter to run.
Can I increase the token limit?
No, the context window limit is set by the model provider for that specific model. To handle more text, you switch to a model with a larger context window or redesign the workflow to retrieve only what is needed.