Introduction
If you have started using AI APIs or building with LLMs, you have probably noticed one thing fast: costs can vary a lot depending on the model and setup. If you are wondering what factors influence the pricing of AI tokens, the short answer is that the bill depends on much more than just how much text you type.
Tokens are the basic billing unit of AI, small chunks of text the model reads, writes, or uses internally while processing a request. The price per token is shaped by around 10 different factors, including model tier, input versus output pricing, context size, hidden system overhead, and provider pricing strategy.
This guide breaks down each factor in plain English so you can understand where the cost comes from and how to make smarter decisions before you ship.
Estimate your AI token costs for free ⇒
TL;DR: The 10 Factors That Determine AI Token Pricing
Here is the short version, these are the 10 factors that affect what you pay per AI token.
- Model size and capability: More advanced models usually cost more because they require more compute and deliver stronger reasoning, accuracy, or multimodal performance.
- Input tokens vs output tokens: Reading your prompt is usually cheaper than generating a response, so output tokens often cost several times more than input tokens.
- Context window size: Models built to handle very large context windows often cost more because they must process and manage more text at once.
- Language and script: Some languages and writing systems use more tokens to express the same meaning, which increases total cost.
- Technical content and data format: Code, tables, JSON, and dense technical text often tokenize less efficiently than plain English prose.
- Reasoning and chain-of-thought processing: Models that perform deeper internal reasoning can consume extra billed tokens and raise the cost of complex tasks.
- Hidden tokens (system prompts, tool definitions, RAG context): A big part of your bill can come from tokens the end user never sees but the model still has to process.
- Prompt caching and batch discounts: Reusing cached prompts and sending non-urgent jobs in batches can materially reduce the effective price you pay.
- Provider pricing strategy and volume tiers: The same or similar model can cost different amounts depending on discounts, commitments, reseller markups, and billing structure.
- Infrastructure costs (compute, storage, energy): Token pricing also reflects the real cost of GPUs, networking, storage, electricity, and cooling behind the scenes.
Let’s break each one down so you actually understand what is going on under the hood.
What Are AI Tokens and Why Do They Cost Money?
AI models do not read words the way humans do. They break text into small chunks called tokens, and each chunk costs money to process.
A simple rule of thumb is that 1 token is about 0.75 English words, or about 4 characters. So a short sentence like The cat sat on the mat becomes approximately 7 tokens, and your bill is based on how many of those chunks the model has to read, generate, or use internally.
How Tokenization Works
Tokenization is the process of splitting text into those smaller pieces. Different AI providers use different tokenization methods, such as BPE for OpenAI models and WordPiece for some Google systems, but the basic idea is the same: break text into predictable chunks the model can process efficiently.
Those chunks are not always full words. For example, a word like tokenization might be split into two tokens, such as token and ization, because the model has learned common subword patterns instead of storing every possible word as a single unit.
Why Different Models Tokenize Differently
Different models can turn the exact same sentence into different token counts. That happens because each model has its own vocabulary, splitting rules, and internal way of encoding text.
This matters for pricing. If one provider breaks your prompt into more tokens than another, your cost can go up even when the visible text stays exactly the same. That is one reason switching models or providers can change your bill faster than beginners expect.
Factor 1: Model Size and Capability
Model choice is usually the biggest pricing driver. A small, fast model like GPT-4.1 Nano can cost a fraction of what a frontier reasoning model costs, even before you look at prompt length or output size.
The reason is simple: stronger models do more work per token. They are built for harder tasks, so providers price them higher from the start.
Factor 2: Input Tokens vs Output Tokens
Every AI request has two billable parts: input tokens and output tokens. Input tokens are the text you send to the model, such as your prompt, instructions, and retrieved context, while output tokens are the text the model sends back, and output tokens almost always cost about 3 to 5 times more.
That pricing split is why chatbots, assistants, and content-generation flows can get expensive fast. A long answer often costs more than a long prompt.
Why Output Tokens Cost More
Input is cheaper because the model is mostly reading and interpreting text that already exists. Output is more expensive because the model has to generate new text one token at a time, predicting each next token sequentially until the response is complete.
That extra generation work takes more computation. In practice, this means controlling response length is one of the easiest ways to reduce token costs without changing your whole setup.
A Quick Cost Example
Take a 500-token prompt sent to GPT-5.4 with a 200-token response. If input is priced at $2.50 per 1 million tokens and output is priced at $15 per 1 million tokens, the math looks like this:
- Input cost: 500 × ($2.50 / 1,000,000) = $0.00125
- Output cost: 200 × ($15 / 1,000,000) = $0.003
- Total cost per request: $0.00425
That number looks tiny until usage scales. At 10,000 daily requests, the same interaction would cost about $42.50 per day, or roughly $1,275 over a 30-day month if usage stayed consistent.
This is why output-heavy applications need tight response controls. Shorter answers, lower max token limits, and better prompt design can have a direct impact on total spend.
Factor 3: Context Window Size
A context window is the amount of text a model can keep in view during a single request. For pricing, it matters twice: larger-window models often start with higher token rates, and large prompts get expensive fast when you keep stuffing more text into each call.
What a Context Window Is
Think of the context window as the model’s short-term memory. It defines how much text the model can see at once, including your prompt, prior messages, uploaded content, and any instructions running behind the scenes.
Small models may offer context windows around 4K to 32K tokens. Standard long-context models often sit around 128K to 200K, and some extended-context models go up to 1M tokens or more.
How Window Size Affects Your Bill
The first cost mechanic is the model itself. Models built to handle very large windows often charge more per token because processing and managing that much text is more demanding.
The second cost mechanic is usage. If you actually fill that window with conversation history, long documents, or retrieved context, you are sending more input tokens every single time.
A chatbot is the easiest example. After 10 turns, you might be sending 15,000 or more tokens of prior history with each new user message, and all of that history counts as billable input tokens again on every request.
That is why context management matters. Summarizing older messages, trimming irrelevant history, and only sending the document chunks the model needs can cut costs directly without changing the user experience much.
Factor 4: Language, Script, and Content Type
Most people assume a word is a word, but token billing does not work that way. The language you write in, whether you send plain prose or code, and even the format of your data can all change token count for the same underlying meaning.
This matters a lot in production. Teams can sometimes cut costs just by sending cleaner inputs, such as CSV instead of JSON for tables, or Markdown instead of YAML for structured instructions.
The same meaning can take more tokens outside English because many tokenizers are more optimized for English text patterns.
Special characters, indentation, formulas, and syntax-heavy strings usually tokenize less efficiently than plain prose.
For similar structured content, Markdown can use roughly fewer tokens than YAML because it adds less formatting overhead.
JSON is easy for systems to parse, but the braces, keys, and repeated structure can increase token count compared with Markdown.
If you are sending tabular data to a model, CSV can be much more token-efficient than JSON for the same rows and columns.
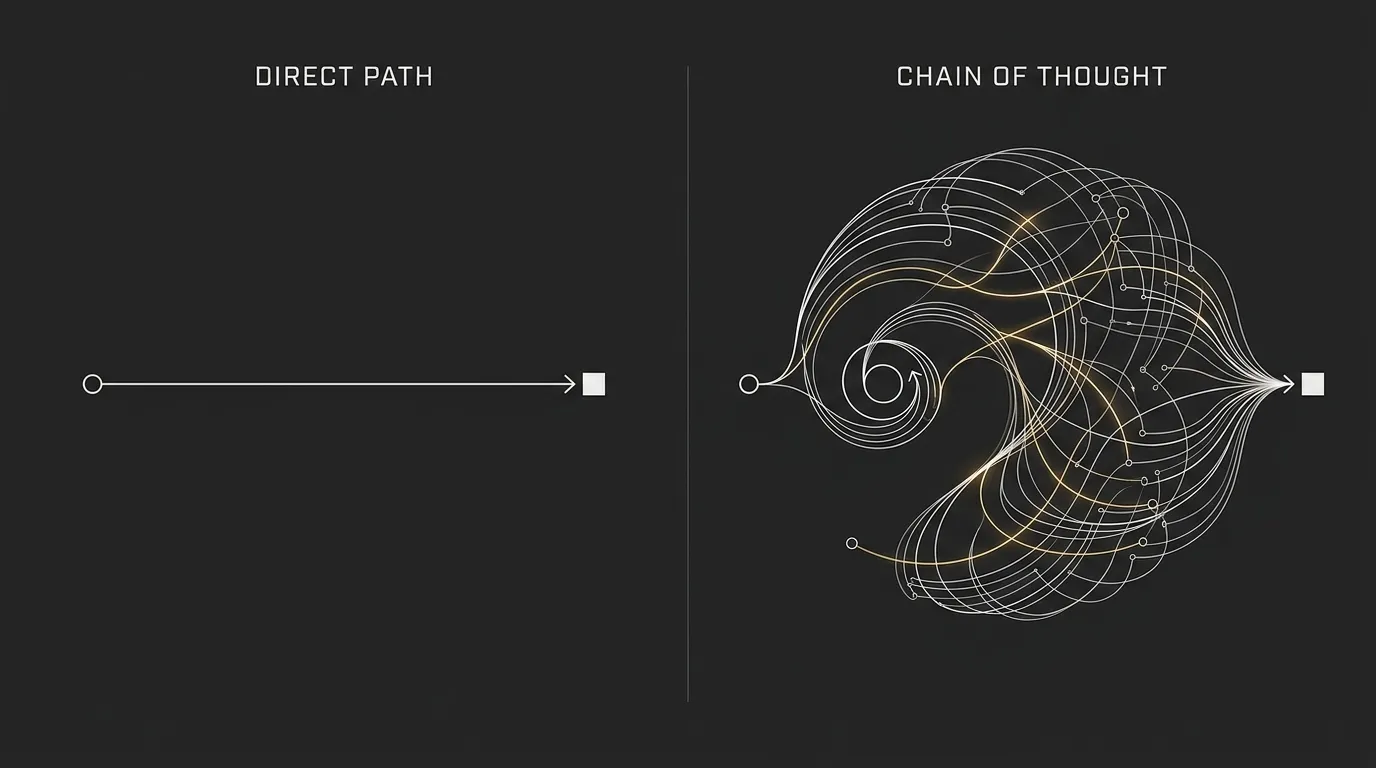
Factor 5: Reasoning Tokens and Chain-of-Thought Processing
Some newer models, such as OpenAI’s o-series or GPT-5 reasoning mode, do more than read your prompt and generate a reply. They also produce internal thinking tokens as part of a chain-of-thought style reasoning process, and those reasoning tokens can be billed separately.
That is where costs can jump fast. Reasoning tokens can cost around 10 to 30 times more than standard output tokens, which makes advanced reasoning models a very different pricing category from normal chat models.
A simple way to think about it is this: it is like asking someone to show their working on a math problem. The final answer may be short, but all the intermediate steps still take time and effort, and in this case they can also add to your bill.
This is why a single hard query can cost dramatically more on a reasoning model than on a standard model, even if the visible answer looks similar in length. The extra cost comes from the internal work required to solve the problem, not just from the final response you see.
For teams moving from standard chat models to reasoning models, this is one of the easiest pricing surprises to miss. If your app handles code generation, multi-step analysis, planning, or complex decision support, reasoning tokens can become a major part of total spend very quickly.
Factor 6: Hidden Tokens You Might Not Know You’re Paying For

The tokens you type and the tokens you see in the reply are not the only tokens you pay for. In many AI apps, hidden token usage can add roughly 20 to 40% to actual costs once you account for instructions, tools, retrieved content, and chat history.
That is why bills often look higher than a simple prompt-plus-response estimate. Understanding these invisible inputs is the first step to getting costs under control.
System Prompts
Most production AI apps send a system prompt behind the scenes. This is the instruction block that tells the model how to behave, what rules to follow, what tone to use, and what not to do.
That hidden prompt can add around 500 to 3,000 tokens to every request. If the app runs on every user interaction, that overhead repeats every single time whether the user sees it or not.
Tool and Function Definitions
If the model can call tools, APIs, or functions, those tool definitions also consume tokens. For example, a support bot that can search orders, check account status, and open tickets may send all of those tool descriptions along with the request.
A bot with 10 tools might add roughly 2,000 to 5,000 extra tokens per request just from tool metadata. The user never sees those definitions, but they still count toward billing.
RAG Retrieved Context
Retrieval-augmented generation (RAG) adds another hidden layer. When the system pulls in help docs, policy text, product specs, or knowledge base chunks to improve the answer, those retrieved passages are appended to the prompt and billed as input tokens.
Depending on the setup, retrieved context can add around 2,000 to 10,000 tokens per query. This is one of the main reasons document chat and knowledge assistants can get expensive fast.
Conversation History
Chat history is another quiet cost multiplier. Every new message often includes all or most of the earlier messages again so the model can stay aware of the conversation.
That means the same old tokens keep getting resent and rebilled with each turn. If history is not summarized or trimmed, costs compound quickly, especially in long support chats, copilots, and internal assistant workflows.
Factor 7: Provider Pricing Strategy, Volume Tiers, and Discounts
Even after model choice, token type, and context size, the provider’s own pricing structure still has a big impact on what you pay. Two teams can send similar workloads to similar models and still end up with very different bills because of caching rules, batch discounts, usage tiers, or reseller markup.
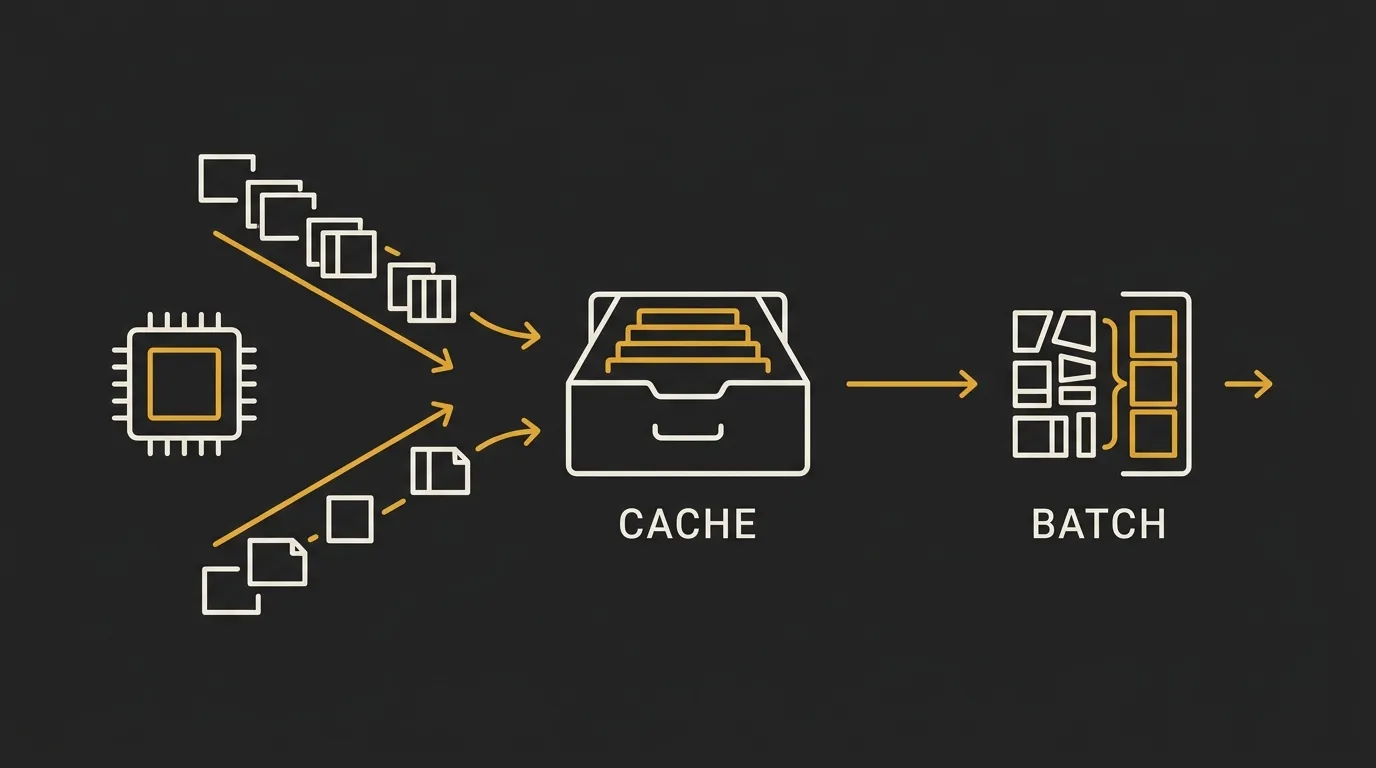
Caching Discounts
Prompt caching can reduce costs when you reuse the same input repeatedly, especially large system prompts or shared context blocks. If a provider caches that content after the first request, later reads can cost roughly 90% less than the original uncached read.
There is a catch. Cache writes can cost slightly more, often around 1.25 to 2 times the normal input rate, so caching only saves money when the same content gets reused enough times to offset that first write.
A simple example is a support assistant with a long system prompt, policy rules, and tool instructions. If that same block is sent on every request, caching can turn a repeated cost into a much smaller one.
Batch Processing Discounts
Batch processing is a straightforward trade-off: lower cost in exchange for slower turnaround. Many providers offer around 50% discounts if you submit a large set of requests together and accept delayed processing, often with a window of up to 24 hours instead of real-time responses.
This works well for jobs that do not need an instant reply. Good examples include document analysis, content generation, classification, tagging, and back-office data pipelines.
If the request powers a live chatbot, batch mode is usually not an option. But for overnight or scheduled jobs, it can be one of the simplest cost reductions available.
Volume Tiers and Commitments
Many providers also reduce per-token pricing as your usage grows. It works a bit like bulk buying: your first block of usage may cost one rate, and higher-volume usage may qualify for lower rates or custom contracts.
This is one reason startups and enterprise teams can pay very different effective prices for the same model. Higher commitments, reserved spending, or negotiated contracts can materially change the final cost per token.
There is also a channel effect. The same model accessed through a cloud marketplace such as AWS Bedrock or Azure may carry additional markup compared with buying directly from the model provider, so the delivery route matters as much as the model itself.
Factor 8: Infrastructure Costs Behind the Token Price

Every token price includes more than model intelligence. It also includes the physical infrastructure running the model, and those underlying costs can vary a lot by provider, region, and deployment setup.
That is one reason the same model can be priced differently across platforms. The bill is shaped not just by software, but by the hardware, data center design, and operating efficiency behind it.
Compute (GPUs)
Modern AI models run on specialized processors, usually GPUs, that are expensive to buy, maintain, and keep fully utilized. These chips handle the heavy math required to process prompts and generate tokens.
Faster GPUs can reduce time per token and improve throughput, but they also cost more. Providers price that into their rates, especially for higher-end models that need top-tier hardware to perform well at scale.
Storage and Networking
AI systems also depend on fast storage and very low-latency networking to keep data moving efficiently between components. If storage is slow or networking adds delays, GPUs can sit idle waiting for data instead of generating output.
That inefficiency raises the real cost of serving each token. Providers with newer, more optimized infrastructure can operate more efficiently, while legacy setups may carry extra overhead that shows up in pricing.
Power and Cooling
Large AI clusters consume a huge amount of electricity and generate a lot of heat. Next-generation GPU racks need serious power delivery and specialized cooling systems to run reliably.
Those costs are not separate from token pricing, they are built into it. According to Deloitte, about 50% of the cost of an on-premise AI factory can come from non-GPU factors such as networking, power, cooling, facilities, and the software stack.
For beginners, the main takeaway is simple: token prices are partly an infrastructure story. If one provider charges more than another for similar model access, the difference may come from the physical environment and operating model behind the API, not just from the model itself.
How to Estimate and Control Your AI Token Costs
Now that the main pricing drivers are clear, the next step is turning that knowledge into a practical cost system. The easiest place to start is before you build: use tokenizer tools and calculators to estimate token counts, compare models, and project monthly spend before making a single API call.
That early estimate helps you avoid expensive architecture decisions later. Tools like AI Token Calculator are useful here because they let you test prompt length, model choice, and usage patterns before real traffic starts.
Choose the Right Model for the Job
Use lower-cost models like GPT-4.1-Nano Mini or Gemini Flash for simple classification, summarization, and routine chat. Keep premium reasoning models for harder tasks where the extra capability actually changes the outcome.
Write Shorter, Clearer Prompts
Cut filler words, pleasantries, repeated instructions, and long background text the model does not need. A prompt that is roughly 70% shorter can still produce similar quality while costing far less.
Control Response Length
Tell the model exactly how long the answer should be, for example, answer in 2 sentences or return 5 bullet points. This keeps expensive output tokens from drifting far beyond what the task requires.
Manage Context and History
Summarize older chat turns instead of resending the full thread, and trim documents before sending them. This is one of the biggest savings levers for chatbots, copilots, and document analysis workflows.
Use Caching and Batching When Available
Enable prompt caching for repeated system prompts and shared instructions, then batch non-urgent jobs when the provider offers lower pricing. For offline workloads, batch processing can cut costs by around 50%.
What’s Next: Token Prices Are Dropping, but Total Spend Is Rising
There is a real paradox in AI pricing right now. Per-token prices are falling fast, and some analyses point to annual declines on the order of 200x, but total AI spend keeps climbing because usage is growing even faster. More teams are deploying AI, more workflows are becoming multi-step, and more requests now include long context, tools, retrieval, and reasoning overhead.
What matters next depends on your role. If you are a developer building a chatbot, focus on context management and model routing, because long histories and sending every query to a premium model are two of the fastest ways to inflate costs. If you are a business leader evaluating AI budgets, focus on hidden tokens, provider pricing tiers, and where reseller markup may be creeping in. If you are just getting started, keep it simple: pick the right model for the task, write tighter prompts, and control response length before you worry about advanced optimization.
If you want to see exactly how these factors affect your costs in real numbers, try running your prompts through a token cost calculator before your next project. That gives you a much clearer view of likely spend before architecture decisions get locked in.
Start calculating your AI token costs ⇒
Frequently Asked Questions About AI Token Pricing
How much does one AI token cost?
It depends on the model tier and provider. Budget models often range from $0.08 to $0.60 per million tokens, mid-range models from $2 to $15 per million, and premium models from $5 to $75 per million.
The actual rate also depends on whether you are paying for input, output, cached input, or reasoning-related usage. That is why the same request can vary a lot in price across different models.
Why do output tokens cost more than input tokens?
Output tokens usually cost more because generating text requires more computation than reading input. Providers commonly price output at around 3 to 5 times the rate of input for that reason.
In simple terms, the model has to do more work to predict and produce each next token than to process text that is already there. Longer answers are often one of the fastest ways to raise your bill.
Does the language I write in affect token costs?
Yes. Non-English text often uses more tokens than English for the same meaning because most tokenizers are more optimized for English text patterns.
In many cases, non-English prompts can require around 20 to 30% more tokens. That means multilingual apps can carry higher token costs even when the message length looks similar to a human reader.
What are reasoning tokens and why are they so expensive?
Reasoning tokens are internal thinking steps some advanced models generate as part of solving harder problems. These can be billed separately and may cost around 10 to 30 times more than standard output tokens.
That is why a complex reasoning query can cost much more than a normal chat request, even if the final visible answer is short. The extra spend comes from the hidden work the model performs during inference.
Can I reduce my AI token costs without losing quality?
Yes. Most teams can reduce costs by around 30 to 70% through better prompt writing, model routing, caching, and tighter context management.
The key is to match the model to the task, cut unnecessary prompt text, control response length, and avoid resending large histories or documents when a summary would do. Cost reduction usually comes from cleaner system design, not from sacrificing output quality.
Do all AI providers charge the same for the same model?
No. Different providers can charge different rates for similar model access, and cloud resellers such as AWS and Azure may add their own markup.
Pricing also changes based on caching discounts, batch options, volume tiers, and enterprise commitments. So even when the model name looks similar, the effective token cost may not be.
How can I estimate my monthly AI token costs before I start?
Use a token calculator or tokenizer library to estimate how many tokens each request consumes, then multiply that by your expected monthly request volume. After that, add a 30 to 50% buffer for hidden tokens such as system prompts, retrieved context, tool definitions, and conversation history.
This gives you a much more realistic starting forecast than looking only at the visible prompt and reply. If you want a faster estimate, a tool like AI Token Calculator can help you compare models and usage scenarios before launch.